
Operations
Running an AI-Native Studio as a Solo Founder in 2026
An updated, evidence-first view of a solo founder operating two flagships and maintained live properties through one governed AI system.
Blog
Engineering deep dives, product benchmarks, and lessons learned from running 11 AI-powered products as a solo founder. 12 posts.
An updated, evidence-first view of a solo founder operating two flagships and maintained live properties through one governed AI system.

A methodology-first reference for comparison engines that publish sources and decision rules.

A curated reference list using public evidence, Wikidata anchors, and open code/data signals.

Why research outputs are labeled by maturity and datasets are cited by name and license.

Cost structure, infrastructure choices, and where AI-native media economics break down.
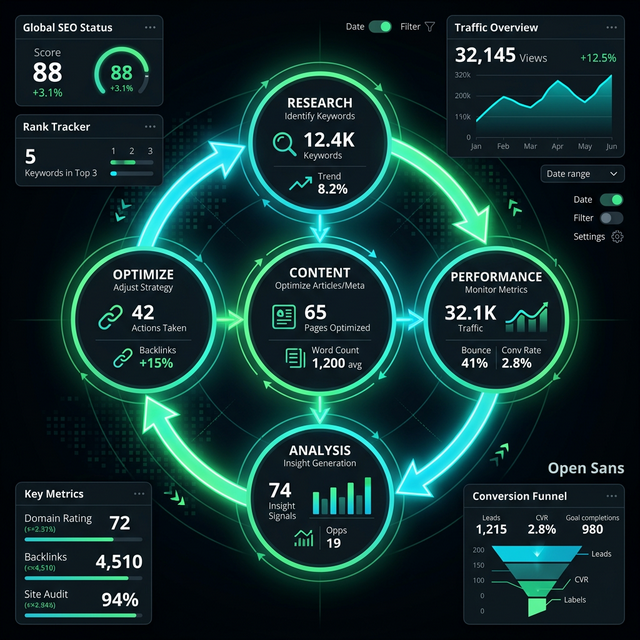
A search-feedback loop that learns from clicks and refreshes content when keywords drift.
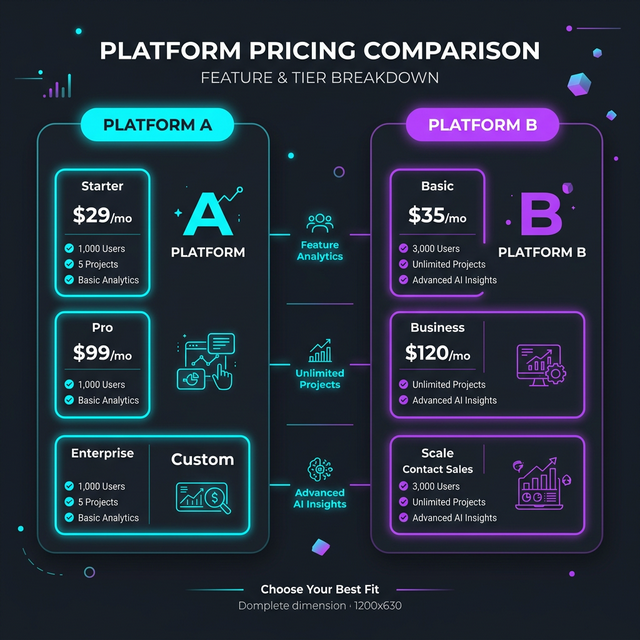
Platform comparison with deploy experience, cold-start behavior, and cost analysis.
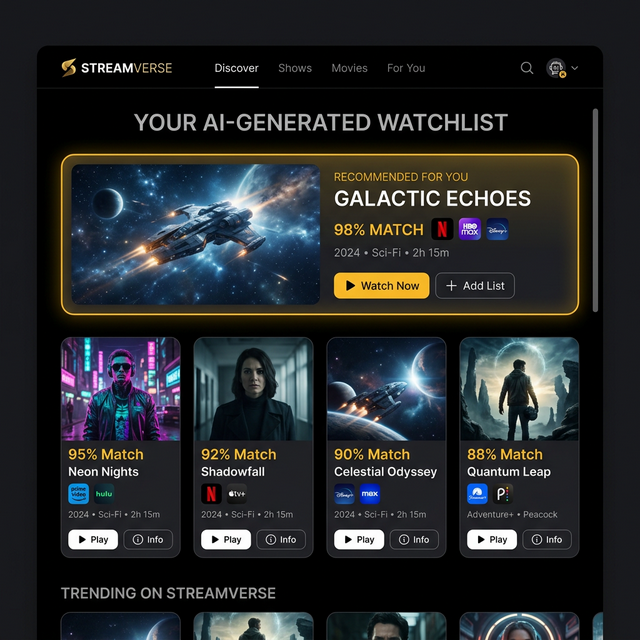
How K-OTT combines streaming metadata and Korean viewing context to support discovery.
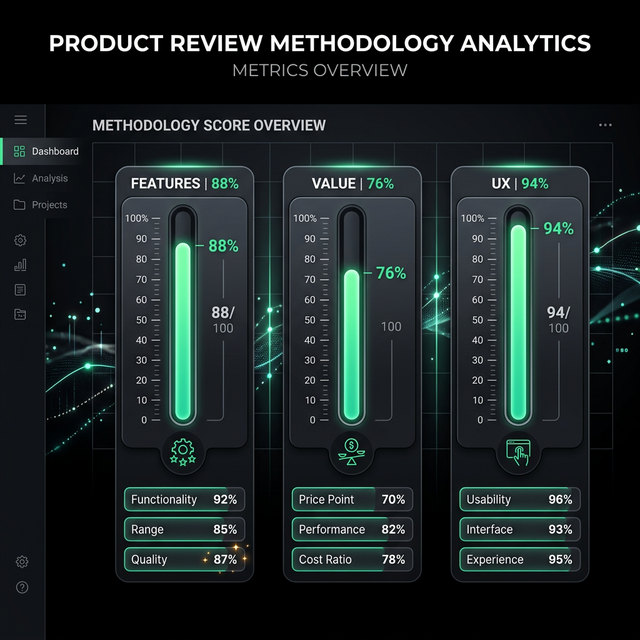
How automated specification analysis and benchmark comparison can produce auditable product reviews.

How research, writing, SEO optimization, quality review, shipping, learning, and refresh work as one governed loop.
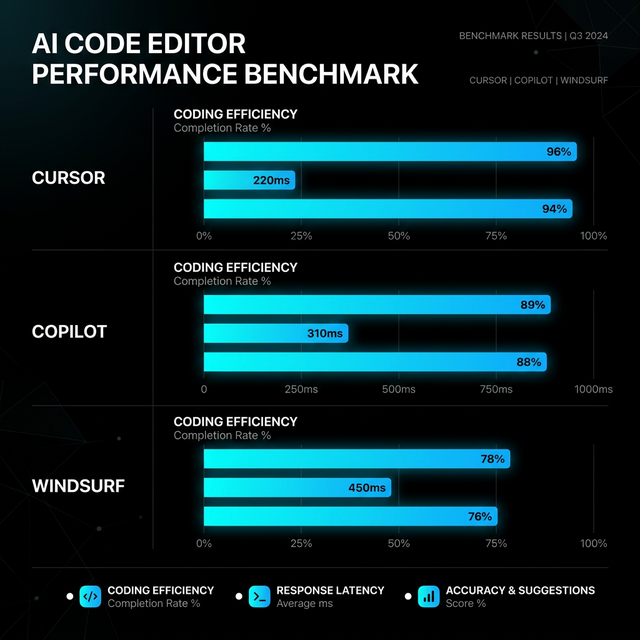
Methodology and results from benchmarking AI editors across structured specifications.
A corrected operating note on concentrating effort around two flagships, maintained infrastructure, and human-governed AI execution.